Definisi Data Mining, Tugas Utama Data Mining, Proses dan Cara Kerja Data Mining,Metodologi Data Mining.
Kemudahan penyimpanan dan pengaksesan data oleh suatu aplikasi
menyebabkan membengkaknya jumlah data yang tersedia. Sudah banyak orang
yang menyadari bahwa data yang berukuran besar tersebut sebenarnya
mengandung berbagai jenis pengetahuan
tersembunyi yang berguna untuk proses pengambilan keputusan. Akan
tetapi, pengetahuan akan sangat sulit ditemukan dengan cara menganalisis
data secara manual. Oleh karena itu, dilakukan data mining untuk
mengekstraksi pengetahuan secara otomatis dari data berukuran besar
dengan cara mencari pola-pola menarik yang terkandung di dalam data
tersebut. Data
mining memiliki banyak fungsionalitas, antara lain pembuatan
ringkasan data, analisis asosiasi antar data, klasifikasi data,
prediksi, dan pengelompokan data. Setiap fungsionalitas akan
menghasilkan pengetahuan atau pola yang berbeda satu sama lain.
Pada klasifikasi, akan dihasilkan sebuah model yang dapat memprediksi
kelas atau kategori dari objekobjek di dalam basisdata. Sebagai contoh,
klasifikasi dapat digunakan oleh petugas peminjaman uang di sebuah bank
untuk memprediksi pemohon mana yang aman dan mana yang beresiko untuk
diberi pinjaman, oleh manajer pemasaran di sebuah toko elektronik untuk
memprediksi apakah seorang pelanggan akan membeli komputer baru, atau
oleh periset di bidang medis untuk memprediksi jenis pengobatan apa yang
cocok diberikan kepada seorang pasien dengan penyakit tertentu. Pada
kasus-kasus tersebut, model klasifikasi dibuat untuk memprediksi kelas
”aman” atau ”beresiko” untuk data permohonan pinjaman; ”beli” atau
”tidak” untuk data pemasaran; dan ”pengobatan-1”, ”pengobatan-2”, atau
”pengobatan-3” untuk data medis. Model klasifikasi dibuat dengan cara
menganalisis training data (terdiri dari objek-objek yang
kelasnya sudah diketahui). Model yang dihasilkan kemudian akan digunakan
untuk memprediksi kelas dari unknown data (terdiri dari
objek-objek yang kelasnya belum diketahui). Model klasifikasi dapat
digambarkan dalam beberapa bentuk, seperti aturan klasifikasi (IF-THEN),
pohon keputusan, rumus matematika, atau jaringan saraf tiruan. Pohon
keputusan banyak digunakan karena mudah dipahami oleh manusia serta
mampu menangani data beratribut banyak.
5. Bahasan Umum Data Mining
Data Mining merupakan teknologi baru yang sangat berguna untuk membantu perusahaan-perusahaan menemukan informasi yang sangat penting dari gudang data mereka
.
Data Mining dapat menjawab pertanyaan-pertanyaan bisnis yang dengan cara tradisional memerlukan banyak waktu untuk menjawabnya. Data Mining mengeksplorasi
basis data untuk menemukan pola-pola yang tersembunyi, mencari
informasi pemrediksi yang mungkin saja terlupakan oleh para pelaku
bisnis karena terletak di luar ekspektasi mereka.
Definisi Data Mining
Data mining didefinisikan sebagai satu set teknik yang
digunakan secara otomatis untuk mengeksplorasi secara menyeluruh dan
membawa ke permukaan relasi-relasi yang kompleks pada set data yang
sangat besar.
Data mining dapat juga didefinisikan sebagai “pemodelan dan
penemuan polapola yang tersembunyi dengan memanfaatkan data dalam volume
yang besar”1. Data mining menggunakan pendekatan discovery-based dimana pencocokan pola (pattern-matching) dan algoritmaalgoritma yang lain digunakan untuk menentukan relasi-relasi kunci di dalam
data yang diekplorasi. Data mining merupakan komponen baru pada arsitektur sistem pendukung keputusan (DSS) di perusahaan-perusahaan. Ruang Lingkup Data Mining
Data mining (penambangan data), sesuai dengan namanya, berkonotasi sebagai
pencarian informasi bisnis yang berharga dari basis data yang sangat besar. Usaha
pencarian yang dilakukan dapat dianalogikan dengan penambangan logam
mulia dari lahan sumbernya. Dengan tersedianya basis data dalam kualitas
dan ukuran yang memadai,
Tugas Utama Data Mining
Telah disebutkan di ruang lingkup data mining bahwa pada
kebanyakan aplikasinya, gol utama dari data mining adalah untuk membuat
prediksi dan deskripsi. Prediksi menggunakan beberapa variabel atau
field-field basis data untuk memprediksi nilai-nilai
variabel masa mendatang yang diperlukan, yang belum diketahui saat
ini. Deskripsi berfokus pada penemuan pola-pola tersembunyi dari data
yang ditelaah. Dalam konteks KDD, deskripsi dipandang lebih penting
daripada prediksi. Ini berlawanan dengan aplikasi pengenalan pola dan
mesin belajar.
Prediksi dan deskripsi pada data mining dilakukan dengan tugas-tugas
utama yang akan dijelaskan di bawah ini. Pada setiap tugas akan
diberikan pointer ke masalah bisnis yang dapat diselesaikan(yang telah
dibahas pada butir 3).
Klasifikasi adalah fungsi pembelajaran yang
memetakan (mengklasifikasi) sebuah unsur (item) data ke dalam salah satu
dari beberapa kelas yang sudah didefinisikan.
Regresi adalah fungsi pembelajaran yang memetakan
sebuah unsur data ke sebuah variabel prediksi bernilai nyata. Aplikasi
dari regresisi ini misalnya adalah pada prediksivolume biomasa di hutan
dengan didasari pada pengukuran gelombang mikro penginderaan jarak jauh
(remotely-sensed), prediksi kebutuhan kustomer terhadap sebuah produk
baru sebagai fungsi dari pembiayaan advertensi, dll.
Pengelompokan (clustering) merupakan tugas deskripsi yang banyak digunakan dalam
mengidentifikasi sebuah himpunan terbatas pada kategori
ataucluster untuk mendeskripsikan data yang ditelaah. Kategori-kategori
ini dapat bersifat eksklusif dan ekshaustif mutual, atau mengandung
representasu yang lebih kaya seperti kategori yang hirarkis atau saling
menumpu (overlapping).
Peringkasan melibatkan metodologi untuk menemukan deskripsi yang
ringkas dari sebuah himpunan data. Satu contoh yang sederhana adalah
mentabulasikan mean dan deviasi standar untuk semua field-field tabel.
Pemodelan Kebergantungan adalah penemuan sebuah
model yang mendeskripsikan kebergantungan yang signifikan antara
variabelvariabel. Model kebergantungan ini ada di 2 tingkat: tingkat
structural yang menspesifikasikan variabel variabel yang secara local
bergantung satu sama lain, dan tingkat kuantitatif yang
menspesifikasikan tingkat kebergantungan dengan menggunakan skala
numeric
Pendeteksian Perubahan dan Deviasi berfokus pada penemuanperubahan
yang paling signifikan di dalam data dari nilai-nilai yang telah diukur
sebelumnya.
Teknologi data mining memiliki
kemampuan-kemampuan sebagai
berikut1:
1. Mengotomatisasi prediksi tren dan sifat-sifat bisnis.
Data mining
mengotomatisasi proses pencarian informasi pemprediksi di dalam basis
data yang besar. Pertanyaanpertanyaan yang berkaitan dengan prediksi
ini dapat cepat dijawab langsung dari data yang tersedia.
Contoh dari masalah prediksi ini misalnya target pemasaran, peramalan kebangkrutan dan bentukbentuk kerugian lainnya.
2. Mengotomatisasi penemuan polapola yang tidak diketahui sebelumnya.
Kakas data mining “menyapu” basis data, kemudian mengidentifikasi pola-pola yang sebelumnya tersembunyi dalam satu sapuan. Contoh dari penemuan pola ini adalah analisis pada data penjulan ritel untuk mengidentifikasi produkproduk, yang kelihatannya tidak
berkaitan, yang seringkali dibeli secara bersamaan oleh kustomer.
Contoh lain adalah pendeteksian transaksi palsu dengan kartu kredit dan
identifikasi adanya data anomali
yang dapat diartikan sebagai data salah ketik (karena kesalahan operator).
Proses Data Mining
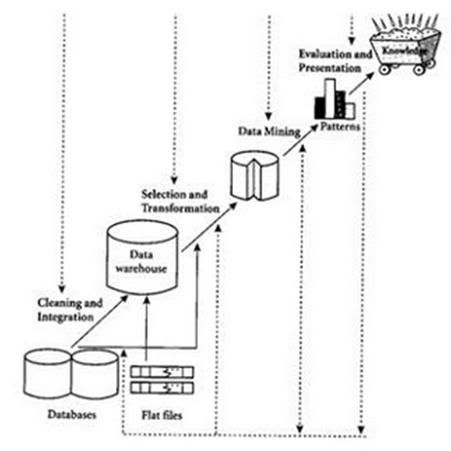
1. Pembersihan data (untuk membuang data yang tidak konsisten dan noise)
2. Integrasi data (penggabungan data dari beberapa sumber)
3. Transformasi data (data diubah menjadi bentuk yang sesuai untuk di-mining)
4. Aplikasi teknik DM
5. Evaluasi pola yang ditemukan (untuk menemukan yang menarik/bernilai)
6. Presentasi pengetahuan (dengan teknik visualisasi)
Tahap-tahap diatas, bersifat interaktif di mana pemakai terlibat langsung atau dengan perantaraan knowledge base.
Knowledge Discovery and Data Mining(KDD) adalah proses yang dibantu oleh komputer untuk menggali dan menganalisis sejumlah besar himpunan data dan mengekstrak informasi dan pengetahuan yang berguna. Data mining tools memperkirakan perilaku dan tren masa depan, memungkinkan bisnis untuk membuat keputusan yang proaktif dan berdasarkan pengetahuan. Data mining tools mampu menjawab permasalahan bisnis yang secara tradisional terlalu lama untuk diselesaikan. Data mining tools menjelajah database untuk mencari pola tersembunyi, menemukan infomasi yang prediktif yang mungkin dilewatkan para pakar karena berada di luar ekspektasi mereka.
Proses dalam KDD adalah proses yang digambarkan pada dan terdiri dari rangkaian proses iteratif sebagai berikut:
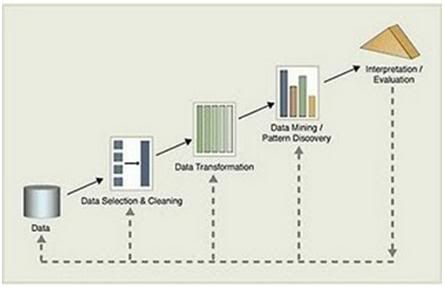
1. Data cleaning, menghilangkan noise dan data yang inkonsisten.
2. Data integration, menggabungkan data dari berbagai sumber data yang berbeda
3. Data selection, mengambil data yang relevan dengan tugas analisis dari database
4. Data transformation, Mentransformasi atau menggabungkan data ke dalam bentuk yang sesuai untuk penggalian lewat operasi summary atau aggregation.
5. Data mining, proses esensial untuk mengekstrak pola dari data dengan metode cerdas.
6. Pattern evaluation, mengidentifikasikan pola yang menarik dan merepresentasikan pengetahuan berdasarkan interestingness measures.
7. Knowledge presentation, penyajian pengetahuan yang digali kepada pengguna dengan menggunakan visualisasi dan teknik representasi pengetahuan.
Cara Kerja Data Mining
Bagaimana tepatnya data mining “menggali” hal-hal penting yang belum diketahui sebelumnya atau memprediksi apa yang akan terjadi?
Teknik yang digunakan untuk melaksanakan tugas ini disebut pemodelan. Pemodelan di sini
dimaksudkan sebagai kegiatan untuk membangun sebuah model pada situasi yang telah diketahui “jawabannya” dan kemudian menerapkannya pada situasi lain yang akan dicari jawabannya. Sebagai contoh di sini diambil pencarian solusi bisnis di bidang telekomunikasi. Ada beberapa perusahaan telekomunikasi yang beroperasi di sebuah negara dan dimisalkan pihak manajemen sebuah perusahaan bermaksud untuk menjaring kustomer baru untuk jasa layanan sambungan langsung jarak jauh (SLJJ). Pihak manajemen dapat “menghubungi” calon-calon kustomer dengan memilih secara acak kemudian menawari mereka dengan diskon khusus, dengan hasil yang kemungkinan besar kurang menggemberikan, atau dengan memanfaatkan pengalaman-pengalaman bisnis yang saat ini sudah tersimpan di basis data perusahaan untuk membangun sebuah model. Perusahaan ini telah memiliki banyak informasi mengenai kustomer perusahaan tersebut: umur, jenis kelamin, sejarah penggunaan fasilitas kredit dan penggunaan SLJJ. Juga sudah diketahui informasi mengenai calon-calon kustomer: umur, jenis kelamin, sejarah penggunaan fasilitas
kredit, dll. Masalahnya adalah penggunaan SLJJ untuk para calon kustomer ini belum diketahui, karena mereka saat ini menjadi kustomer dari perusahaan lain. Yang dipikirkan pihak manajemen adalah mencari calon kustomer yang akan menggunakan banyak jasa SLJJ. Usaha untuk mencari jawaban masalah ini dilakukan dengan membangun sebuah model.
Tabel 1. Data Mining untuk Menentukan Prospek
Status | Kostumer | Prospek |
informasi umum (contoh: data demografis) | Diketahui | Diketahui |
informasi khusus (contoh: trasaksi kustomer) | Diketahui | Target |
Gol dari pemodelan ini adalah untuk membuat perkiraan yang didasari kalkulasi untuk mengisi informasi di kuadran kanan bawah pada Tabel 1, berdasar pada informasi umum dan khusus yang sudah ada (dimiliki oleh perusahaan itu). Misalnya, sebuah model sederhana untuk perusahaan telekomunikasi itu adalah: 98% kustomer “milik” perusahaan itu yang berpenghasilan $60.000/tahun membelanjakan lebih dari $80/bulan untuk penggunaan SLJJ. Model ini kemudian dapat diterapkan untuk menarik kesimpulan dari informasi khusus (sebagai data prospek), dimana saat ini informasi khusus tersebut tidak dimiliki oleh perusahaan. Dengan model ini, calon-calon kustomer baru dapat ditarget secara selektif.
Metodologi Data Mining yang populer
Ada banyak metodologi data mining, tapi di sini hanya akan dibahas yang popular saja. Bahasan metodologi akan meliputi segi representasi model, evaluasi model dan metodologi pencarian.
a.Aturan dan Pohon Keputusan
Metodologi ini, yang menggunakan pemisahan (split) univariate, mudah dipahami oleh pemakai karena bentuk representasinya yang sederhana.. Akan tetapi, batasan-batasan yang diterapkan pada representasi aturan dan pohon tertentu dapat secara signifikan membatasi bentuk fungsional dari model. Memberikan ilustrasi mengenai efek penerapan pemisahan, yang didasarkan pada nilai ambang tertentu, pada variable penghasilan (income) di himpunan data peminjaman: sangat jelas terlihat bahwa penerapan pemisahan nilai ambang sederhana sangat membatasi tipe batas (boundary) klasifikasi yang dapat dihasilkan.
Jika ruang model dilebarkan untuk memfasilitasi ekspresi-ekspresi yang lebih umum (misalnya multivariate hyperplanes pada berbagai sudut), maka model ini menjadi lebih canggih untuk prediksi. Hanya saja, mungkin akan lebih sulit untuk dipahami pemakai.
Metodologi ini terutama digunakan untuk pemodelan prediksi, keduanya untuk klasifikasi dan regresi4. Selain itu, dapat digunakan juga untuk pemodelan deskripsi ringkasan.
b. Metodologi Klasifikasi dan Regresi
Non-linier Kedua metodologi ini terdiri dari sekumpulan teknik-teknik untuk memprediksi kombinasi variabel-variabel masukan yang pas dengan kombinasi linier dan non-linier pada fungsi-fungsi dasar (sigmoid, splines, polinomial). Contohnya antara lain adalah jaringan saraf feedforward, metodologi spline adaptif, dan proyeksi regresi pursuit. menunjukkan tipe boundary keputusan non-linier yang mungkin dihasilkan oleh jaringan saraf . Metodologi regresi non-linier, walaupun canggih dalam representasinya, mungkin sulit untuk diinterpretasikan
Contoh boundary klasifikasi yang “dipelajari” pengklasifikasi non-linier4
c. Metodologi Berbasis-sampel
Representasi dari metodologi ini cukup sederhana: gunakan sampel dari basisdata untuk mengaproksimasi sebuah model, misalnya, prediksi sampel-sampel baru diturunkan dari properti sampel-sampel yang “mirip” di dalam model yang prediksinya sudah diketahui. Teknik ini misalnya adalah klasifikasi tetangga terdekat, algoritma regresi dan system reasoning berbasis-kasus. Gambar 6 menunjukkan hasil dari klasifikasi tetangga terdekat pada himpunan data peminjaman: kelas pada setiap titik di dalam ruang 2-dimensi sama dengan kelas dari titik terdekat di dalam himpunan data yang ditelaah dan orisinil.
Boundary klasifikasi untuk pengklasifikasi tetangga-terdekat
pada himpunan data peminjaman4.
Kekurangan pada metodologi berbasis sampel (misalnya jika dibandingkan dengan berbasis-pohon) adalah dibutuhkannya metrik jarak yang akurat untuk mengevaluasi jarak antara titik-titik data.
d. Model Kebergantungan Grafik Probabilistik
Model grafik menspesifikasikan kebergantungan probabilistik yang mendasari sebuah model dalam menggunakan struktur grafik.
Dalam bentuknya yang paling sederhana, model ini menspesifikasikan variabel-variabel mana yang bergantung satu sama lain. Pada umumnya, model ini digunakan dengan variabel kategorial atau bernilai diskret, tapi pengembangan untuk kasus khusus, seperti densitas Gausian, untuk variabel yang bernilai real (pecahan) juga dimungkinkan. Baru-baru ini riset di bidang inteligensia buatan dan statistic dilakukan untuk mencari teknik dimana struktur dan parameter-parameter pada model grafik “dipelajari” secara langsung dari basis data.
e. Model Belajar Relasional
Jika aturan dan pohon-keputusan memiliki sebuah representasi yang terbatas pada logika proporsional, pembelajaran relasional (yang juga dikenal sebagai pemrograman logika induksi) menggunakan bahasa pola yang lebih sederhana dengan logika tingkatsatu. Pembelajar relasional dengan mudah dapat menemukan formula seperti X=Y. Kebanyakan riset pada metodologi evaluasi model untuk pembelajaran relasional bersifat logik.
Beberapa contoh bidang-bidang bisnis yang telah berhasil menerapkan aplikasi data mining adalah:
a) Perusahaan farmasi dapat menganalisis aktivitas penjualan terkininya dan menggunakan hasilnya untuk mentargetkan dokterdokter yang berpotensi menggunakan produknya dan menentukan aktifitas pemasaran yang paling efektif untuk beberapa bulan mendatang.
b) Perusahaan kartu kredit dapat memanfaatkan data transaksi kustomer-kustomernya untuk merancang produk kredit baru yang akan menarik minat para kustomer tersebut.
c) Perusahaan transportasi yang menyediakan berbagai jenis pelayanan. Data mining dapat digunakan untuk mengidentifikasi prospek-prospek pelayanan yang menjanjikan keuntungan.
d) Perusahaan produk makanan atau kebutuhan sehari-hari. Data mining dapat dimanfaatkan untuk meningkatkan penjualan produk ke para pengecer (retailer). Data kustomer, pengiriman, aktivitas kompetitor dapat digunakan untuk menganalisis sebab-sebab kustomer berpindah ke produk merek lain. Kemudian, hasilnya dapat digunakan untuk menyusun strategi pemasaran yang lebih efektif.
Walaupun telah banyak diaplikasikan di dunia bisnis dan mendatangkan profit, teknologi KDD dan Data Mining masih memiliki tantangan-tantangan yang harus diatasi. Riset untuk menyempurnakan KDD diperlukan antar lain untuk mengatasi4:
a) Basisdata yang berukuran besar, dengan ratusan tabel, jutaan record dan berukuran sampai dengan multigigabyte.
b) Dimensi yang besar, basisdata tidak hanya memiliki jutaan rekord tetapi juga jumlah field (atribut, variabel) yang besar.
c) Data dan pengetahuan yang berubah terus sehingga pola-pola yang telah ditemukan sebelumnya menjadi tidak berlaku lagi.
d) Data yang hilang dan banyak salah, hal ini banyak terjadi pada basisdata.
e) Relasi antar-field basisdata yang kompleks. Saat ini data miningmasih dirancang untuk relasi yang cukup sederhana.
f) Integrasi dengan sistem lain. Sistem KDD standalone bisa jadi agak kurang bermanfaat. Integrasi yang dimaksud bisa terjadi dengan DBMS, kakas-kakas spreadsheet dan visualisasi, serta pencatat sensor waktu-nyata.
Sumber :
http://www.informatika.org/~rinaldi/Matdis/2008-2009/Makalah2008/Makalah0809-039.pdf
http://www.gudangmateri.com/2009/12/proses-dan-cara-kerja-data-mining.html
http://niesha30.wordpress.com/2010/06/18/metodologi-data-mining/
http://denissopyan2004.blogspot.com/2008/11/data-mining.html
 Posted by
Laviola
Posted by
Laviola








